
打破Agent训练瓶颈!人大&至知研究院开源Claw Agent数据+训练+评测全链条
打破Agent训练瓶颈!人大&至知研究院开源Claw Agent数据+训练+评测全链条大模型从“回答问题”走向“完成任务”,正在面临以下瓶颈:面向Claw Agents的数据、训练和评测都比传统environment training更难。为了解决该问题,中国人民大学、至知研究院等最新提出ClawGym——
来自主题: AI技术研报
6979 点击 2026-05-31 11:42
 搜索
搜索
大模型从“回答问题”走向“完成任务”,正在面临以下瓶颈:面向Claw Agents的数据、训练和评测都比传统environment training更难。为了解决该问题,中国人民大学、至知研究院等最新提出ClawGym——
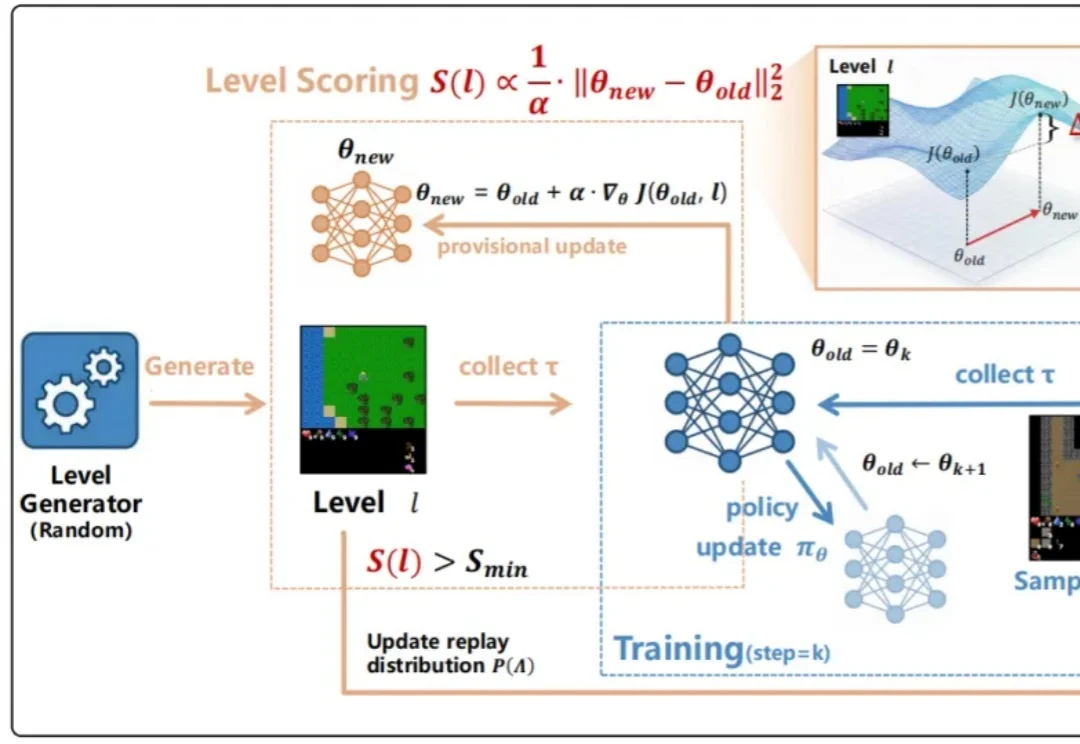
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。

Anthropic、OpenAI等大厂,正计划每年投入10亿美元,教会AI像人类一样工作。他们不仅为AI提供强化学习环境(RL environment,简称gym),还让AI「偷师」各领域专家。OpenAI高管预言,未来「整个经济」,将在某种程度上变成一台「RL机器」。

强化学习核心是什么?Karpathy一语道破——环境。全新开源Environments Hub横空出世,为强化学习训练带去革命性突破。
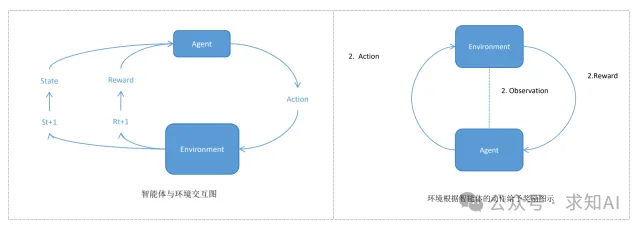
强化学习中的核心概念是智能体(Agent)和环境(Environment)之间的交互。智能体通过观察环境的状态,选择动作来改变环境,环境根据动作反馈出奖励和新的状态。